1、问题描述
测试中发现delete\update语句在并发测试时经常会导致发生死锁。
2、问题分析
在mariadb中,update或delete使用 where(…,…,…) in (…,…,..) 的写法会导致全表扫描,加大锁冲突的概率,造成死锁。
例1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
MariaDB [lzk]> show create table b\G *************************** 1. row *************************** Table: b Create Table: CREATE TABLE `b` ( `a` int(11) NOT NULL DEFAULT '0', `b` int(11) NOT NULL DEFAULT '0', `c` int(11) NOT NULL DEFAULT '0', `d` int(11) NOT NULL DEFAULT '0', `e` int(11) NOT NULL DEFAULT '0', `f` int(11) DEFAULT NULL, PRIMARY KEY (`a`,`b`,`c`,`d`,`e`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin MariaDB [lzk]> explain delete from b where a=1 and b=2 and c=1 and d=1 and e=1; +------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | b | range | PRIMARY | PRIMARY | 20 | NULL | 1 | Using where | +------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ 1 row in set (0.00 sec) --直接根据主键定位到记录 MariaDB [lzk]> explain delete from b where (a,b,c,d,e) in ((1,1,1,1,1)); +------+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | b | ALL | NULL | NULL | NULL | NULL | 18 | Using where | +------+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec) --全表扫描 |
场景1:
当会话1:start transaction;
delete from b where (a,b,c,d,e) in ((1,1,1,1,1));
会话2:start transaction;
delete from b where (a,b,c,d,e) in ((1,1,2,1,1));
此时会话2会产生锁等待。
而场景2:
当会话1:start transaction;
delete from b where where a=1 and b=1 and c=1 and d=1 and e=1;
会话2:start transaction;
delete from b where where a=1 and b=1 and c=2 and d=1 and e=1;
不会产生锁等待。
例2:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
MariaDB [test]> explain update b set c='qwe' where (a,b) in ((1,10)); +------+-------------+-------+-------+---------------+---------+---------+------+---------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+---------+---------+------+---------+-------------+ | 1 | SIMPLE | b | index | NULL | PRIMARY | 8 | NULL | 9278400 | Using where | +------+-------------+-------+-------+---------------+---------+---------+------+---------+-------------+ 1 row in set (0.00 sec)--全索引扫描 MariaDB [test]> explain update b set c='qwe' where a=1 and b=10; +------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ | 1 | SIMPLE | b | range | PRIMARY | PRIMARY | 8 | NULL | 1 | Using where | +------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ 1 row in set (0.00 sec)--直接根据主键定位到记录 |
3、解决办法
不使用delete\update where… in的写法,改为delete\update where … and …or
4、半一致性读仍会死锁问题
在read-committed隔离级别下,update会使用半一致性读,为什么还是有几率发生死锁?
根据场景复现后,show engine innodb status查看死锁信息,发现发生死锁的事务会占有很多锁,不符合innodb半一致读的特性:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
------------------------ LATEST DETECTED DEADLOCK ------------------------ 2016-03-30 15:19:46 7f79e7fec700 *** (1) TRANSACTION: TRANSACTION 132876, ACTIVE 9 sec fetching rows mysql tables in use 1, locked 1 LOCK WAIT 252 lock struct(s), heap size 96696, 226 row lock(s), undo log entries 1 MySQL thread id 5, OS thread handle 0x7f79e8bb5700, query id 15 redhat64-26 10.47.160.26 root updating update test.c set c = '94414' where (a,b) in ((1,'5167')) *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 6 page no 6 n bits 496 index `PRIMARY` of table `test`.`c` trx id 132876 lock_mode X locks rec but not gap waiting Record lock, heap no 211 PHYSICAL RECORD: n_fields 6; compact format; info bits 0 0: len 4; hex 80000001; asc ;; 1: len 4; hex 80000358; asc X;; 2: len 6; hex 00000000c7fb; asc ;; 3: len 7; hex 06000001671e10; asc g ;; 4: len 5; hex 3533343732; asc 53472;; 5: len 3; hex 383536; asc 856;; *** (2) TRANSACTION: TRANSACTION 132878, ACTIVE 9 sec fetching rows mysql tables in use 1, locked 1 98 lock struct(s), heap size 96696, 72 row lock(s), undo log entries 1 MySQL thread id 6, OS thread handle 0x7f79e7fec700, query id 17 redhat64-26 10.47.160.26 root updating update test.c set c = '33764' where (a,b) in ((1,'5250')) *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 6 page no 6 n bits 496 index `PRIMARY` of table `test`.`c` trx id 132878 lock_mode X locks rec but not gap Record lock, heap no 211 PHYSICAL RECORD: n_fields 6; compact format; info bits 0 0: len 4; hex 80000001; asc ;; 1: len 4; hex 80000358; asc X;; 2: len 6; hex 00000000c7fb; asc ;; 3: len 7; hex 06000001671e10; asc g ;; 4: len 5; hex 3533343732; asc 53472;; 5: len 3; hex 383536; asc 856;; *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 6 page no 6 n bits 496 index `PRIMARY` of table `test`.`c` trx id 132878 lock_mode X locks rec but not gap waiting Record lock, heap no 166 PHYSICAL RECORD: n_fields 6; compact format; info bits 0 0: len 4; hex 80000001; asc ;; 1: len 4; hex 8000032b; asc +;; 2: len 6; hex 00000000c5e1; asc ;; 3: len 7; hex 790000019f170a; asc y ;; 4: len 5; hex 3734313133; asc 74113;; 5: len 3; hex 383131; asc 811;; *** WE ROLL BACK TRANSACTION (2) |
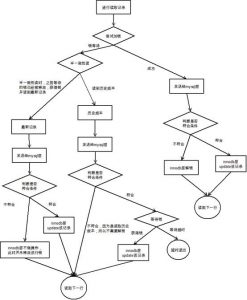
5、Mariadb处理逻辑
在RC隔离级别下,在执行计划为全表扫描或全索引扫描的情况下innodb处理update的流程如下图:

6、源码分析
遍历记录的主函数为row_search_for_mysql()
调用sel_set_rec_lock()尝试加锁
如果加锁时产生锁等待,即:
|
1 2 3 |
case DB_LOCK_WAIT: /* Never unlock rows that were part of a conflict. */ prebuilt->new_rec_locks = 0; //设置锁定的行数为0 |
进行半一致性读:
|
1 |
row_sel_build_committed_vers_for_mysql() |
如果在半一致读时,等待的锁已被释放,则锁读当前版本
|
1 2 3 |
/* The lock was granted while we were searching for the last committed version. Do a normal locking read. */ |
如果读取到历史版本则设置did_semi_consistent_read = TRUE;
根据did_semi_consistent_read的值设置prebuilt->row_read_type
|
1 2 3 4 5 6 7 |
if (UNIV_UNLIKELY(did_semi_consistent_read)) { //读取历史版本,即使用了半一致性读 prebuilt->row_read_type = ROW_READ_DID_SEMI_CONSISTENT; } else { //锁读当前版本 prebuilt->row_read_type = ROW_READ_TRY_SEMI_CONSISTENT; } |
调用解锁函数ha_innobase::unlock_row()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
switch (prebuilt->row_read_type) case ROW_READ_TRY_SEMI_CONSISTENT: //未使用半一致性读 row_unlock_for_mysql(prebuilt, FALSE); break; case ROW_READ_DID_SEMI_CONSISTENT: prebuilt->row_read_type = ROW_READ_TRY_SEMI_CONSISTENT; break; row_unlock_for_mysql() if (prebuilt->new_rec_locks >= 1) { //解锁记录 lock_rec_unlock() } |
但是由于在上面的代码中prebuilt->new_rec_locks的值为0,所以不会对记录解锁!!!
测试MySQL不存在上述问题,应该是这块逻辑与MariaDB不同。